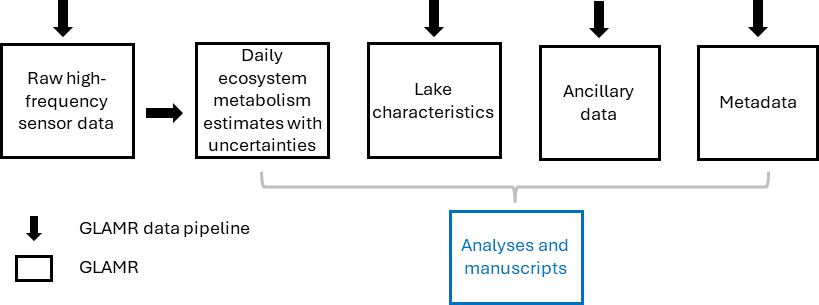
GLAMR includes five primary types of information:
- High-frequency automated sensor measurements of dissolved oxygen concentration, temperature profiles, wind speed, and other variables needed to estimate rates of ecosystem metabolism.
- Modeled time series of daily ecosystem metabolism, with uncertainties.
- Characteristics of the lake and its watershed including area and volume, watershed area and land use, latitude, elevation, etc.
Observed time series of nutrient concentrations, zooplankton abundances, and other limnological characteristics, where available. - Rich metadata in compliance with the Ecological Metadata Language (EML) standard and including, where available, lake identifiers to facilitate links with other publicly available datasets such as HydroLakes (global) and LAGOS-US (United States).
We use the Apache Parquet column-based file format for data types 1 and 2 (high-frequency sensor measurements and daily ecosystem metabolism estimates with uncertainties), to facilitate handling of these large (gigabytes) files. Parquet files are easily readable into R or Python, and have been used previously in similar data repositories (McAfee et al. 2024). Data types 3 and 4 (lake characteristics and time series of supplementary variables) involve smaller files, which are stored as .csv. Data type 5 (metadata) complies with the Ecological Metadata Language (EML) standard.